

BI Stack Example Project
If you opted in to adding the example project during sidetrek init, you should have a fully functional data pipeline already set up.
Let’s take a look at each part of this example project to see what’s going on.
The Tools
This stack consists of the following tools:
- Dagster for orchestration
- Meltano for data ingestion
- DBT for data transformation
- Minio (local replacement for S3) and Apache Iceberg for data storage
- Trino for data querying
- Superset for data visualization
In the example project, all these tools are pre-configured and connected for you.
Data Pipeline Architecture
The data pipeline consists of five components:
- Data Ingestion: First, we extract the data from our source systems (in our example, that’s the example CSV files) and load them into our storage (Minio + Iceberg) using Meltano.
- Data Storage: This is where all the data is stored. We’re using Minio as a local replacement for S3 and Iceberg as the table format on top of Minio.
- Data Transformation: Once the raw data is in our storage, we transform them into analytics-ready tables using DBT and Trino.
- Orchestration: All the above steps are orchestrated by our orchestrator, Dagster.
- Data Visualization: Finally we visualize our data in Superset.
To sum up:
Data sources (e.g. CSV files) -> Ingestion (Meltano) -> Storage (Minio + Iceberg) -> Transformation (DBT + Trino) -> Visualization (Superset)
…all orchestrated by Dagster.
The Dataset
We’ve included a simple dataset with four tables: orders (100k rows), customers (20k rows), products (2k rows), and stores (200 rows). This emulates the typical e-commerce data.
Each table has its own csv file in the /your_project/data directory.
Data Ingestion
Data ingestion is handled by Meltano. Meltano is a managed connector with hundreds of pre-built connectors to popular data sources and targets. Essentially, it handles the EL (“Extract, Load”) part of the ELT process.
As a quick reminder, here’s where Meltano is in the project structure:
your_project
├── .sidetrek
├── .venv
├── superset
├── trino
└── your_project
├── dagster
├── data
├── dbt
└── meltanoMeltano Extractor and Loader
To use Meltano to ingest data, you need to set up two things: 1) an extractor (“tap”) and 2) a loader (“target”).
Taps and Targets?
In our example project, our data is stored in CSV files and we want to load that data into Iceberg tables, so we’re using the tap-csv extractor and target-iceberg loader.
Note that currently, there is no official Meltano target for Iceberg, so we’ve created a custom target. This is also open-source, so feel free to check out the source code here.
Currently, `target-iceberg` only supports APPEND operation!
Adding the Extractor
We’ve already added and configured the extractor for you in the example project, but we’ll go through the setup so you can acquaint yourself with the setup.
To install an extractor, you can run a command like this:
Replace tap-csv with the name of the extractor you want to add. See the Meltano documentation for more information on how to work with Meltano.
Once the extractor is installed, it needs to be configured. We’ve also done this for you in the example project. You can see it in meltano.yml file in the /meltano directory.
...
plugins:
extractors:
- name: tap-csv
...
config:
csv_files_definition: extract/example_csv_files_def.jsoncsv_files_definition field lets Meltano know where to find the CSV files. If you look at that file, you’ll see something like this:
[
{ "entity": "orders", "path": "../data/example/orders.csv", "keys": ["id"] },
{ "entity": "customers", "path": "../data/example/customers.csv", "keys": ["id"] },
{ "entity": "products", "path": "../data/example/products.csv", "keys": ["id"] },
{ "entity": "stores", "path": "../data/example/stores.csv", "keys": ["id"] }
]It basically tells Meltano where to find the CSV files and what the primary keys are for each table.
Adding the Loader
Once the extractor is set up, it’s time to add the loader. This is where you tell Meltano where to load the data to.
In the example project, we’re loading the data into Iceberg tables. We’ve already added and configured the loader for you in the example project, but if you want to add your own later, you can do it like this:
Note that you typically don’t need the --custom flag if you’re using one of the existing Meltano loaders.
Configuring the loader is similar to configuring the extractor. You can find the configuration in the meltano.yml file in the /meltano directory.
...
plugins:
...
loaders:
- name: target-iceberg
namespace: target_iceberg
pip_url: git+https://github.com/SidetrekAI/target-iceberg@bugfix/fields
executable: target-iceberg
config:
add_record_metadata: true
aws_access_key_id: $AWS_ACCESS_KEY_ID
aws_secret_access_key: $AWS_SECRET_ACCESS_KEY
s3_endpoint: http://localhost:9000
s3_bucket: lakehouse
iceberg_rest_uri: http://localhost:8181
iceberg_catalog_name: icebergcatalog
iceberg_catalog_namespace_name: rawIt requires AWS credentials, an S3 endpoint (which is a Minio endpoint in our case since we’re using Minio as an S3 replacement for our development environment), and Iceberg-related configurations.
Iceberg is a table format that sits on top of a physical storage layer like S3. When you load data into Iceberg tables, the actual data is stored as files in S3, and Iceberg specifies how those files are organized into tables we’re familiar with.
In essence, Iceberg turns object storage like S3 into a data warehouse.
This is why this loader requires AWS credentials and a Minio endpoint, not just Iceberg configurations.
To learn more about how Iceberg works, check out the Iceberg documentation.
Running Meltano Ingestion
Now that we have the Meltano extractor and loader installed and configured, we can run the ingestion.
You can run it manually by executing the following command:
sidetrek run here is a simple convenience wrapper around meltano run * command. It runs the meltano CLI inside the project virtual env and also sets the cwd to /meltano directory.
It’s identical to running:
Running Meltano Ingestion Inside the Dagster Pipeline
We saw how we can trigger the ingestion manually with the CLI, but often we want to run the ingestion inside the orchestrator (Dagster). For example, we might want to schedule the ingestion to run daily.
In the example project, we’ve already added a job to run the Meltano ingestion in the Dagster pipeline.
import os
from dagster import Definitions
from dagster_dbt import DbtCliResource
from .dbt_assets import dbt_project_assets, dbt_project_dir
from .meltano import run_csv_to_iceberg_meltano_job
defs = Definitions(
assets=[dbt_project_assets],
jobs=[run_csv_to_iceberg_meltano_job],
resources={
"dbt": DbtCliResource(project_dir=os.fspath(dbt_project_dir)),
},
)If you follow the code to run_csv_to_iceberg_meltano_job function above, you’ll see that we’ve added a Dagster job to run meltano.
...
@job(resource_defs={"meltano": meltano_resource}, config=default_config)
def run_csv_to_iceberg_meltano_job():
tap_done = meltano_run_op("tap-csv target-iceberg")()As you can see here, this is simply running the Meltano CLI inside a Dagster job.
In the example project, this is all we’ve done, but for your own data pipeline, you can easily add scheduling on top of this job to run it daily or hourly.
Finally, let’s run the Meltano ingestion job inside Dagster.
- Go to the Dagster dashboard at http://localhost:3000 and click on the
run_csv_to_iceberg_meltano_jobjob
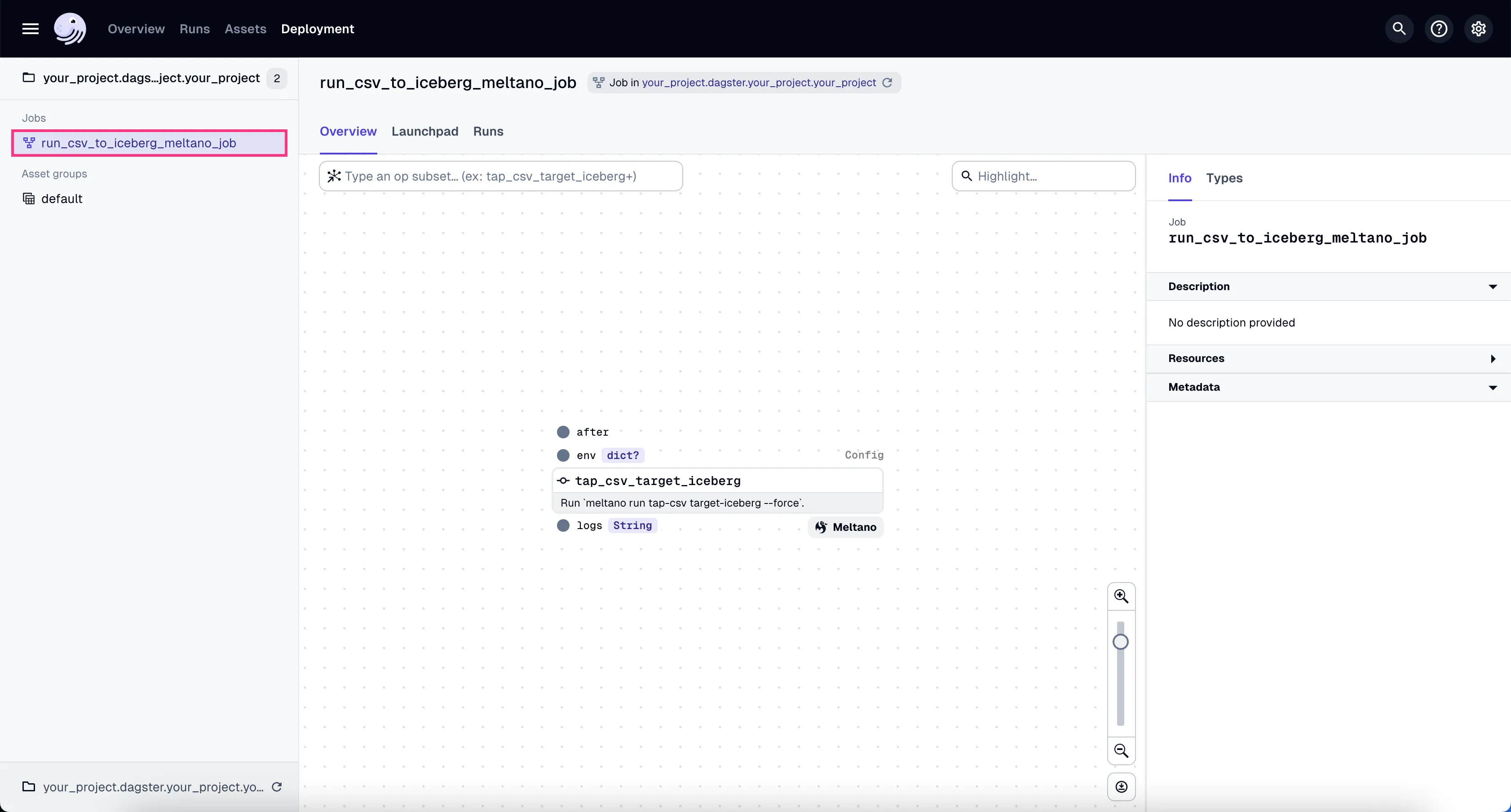
- Go to the tab “Launchpad” and click “Launch Run”.
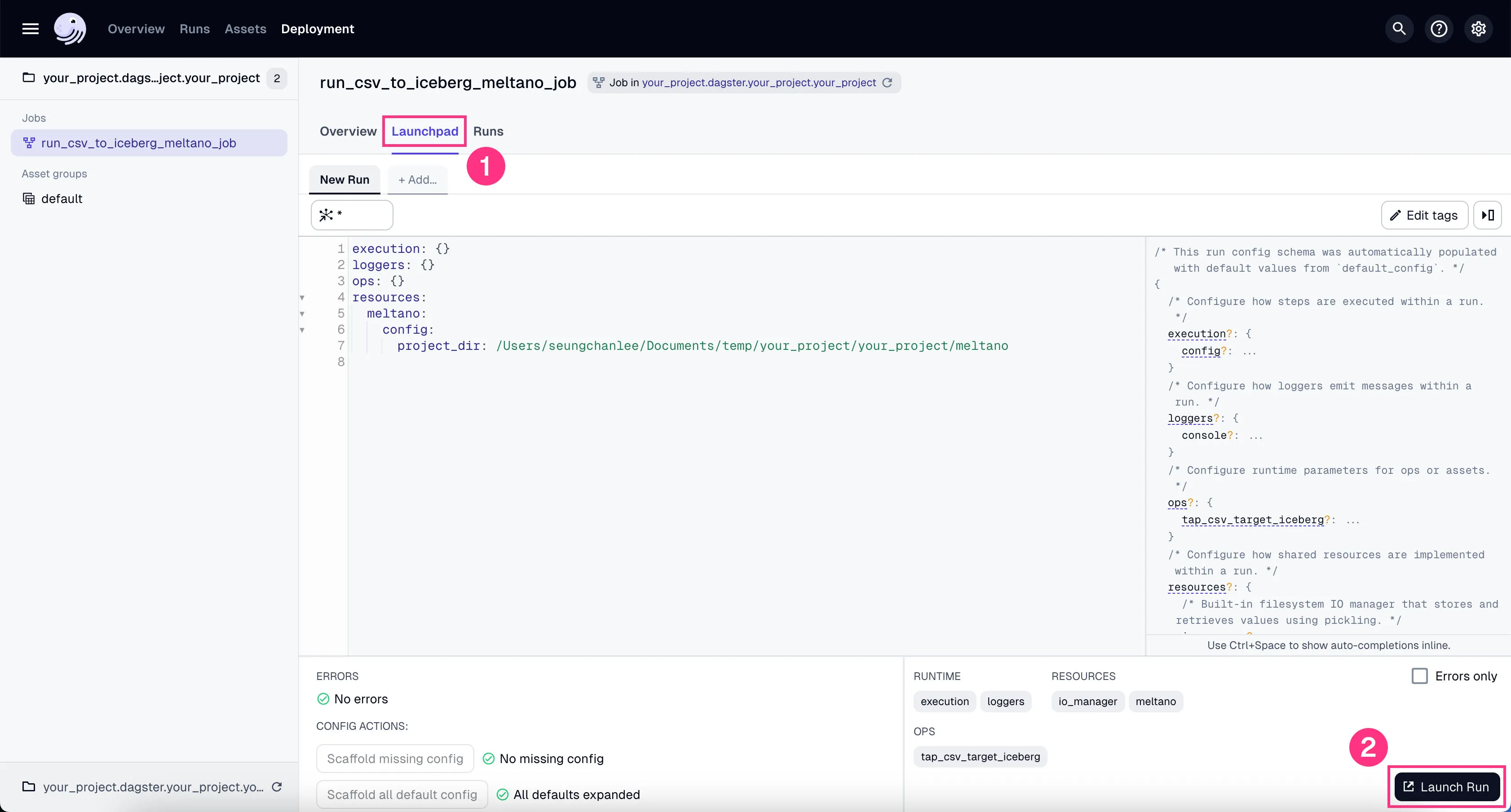
You’ll see the job starts running. It might take a couple of minutes to finish the ~100k rows of data we’re using in our example project.
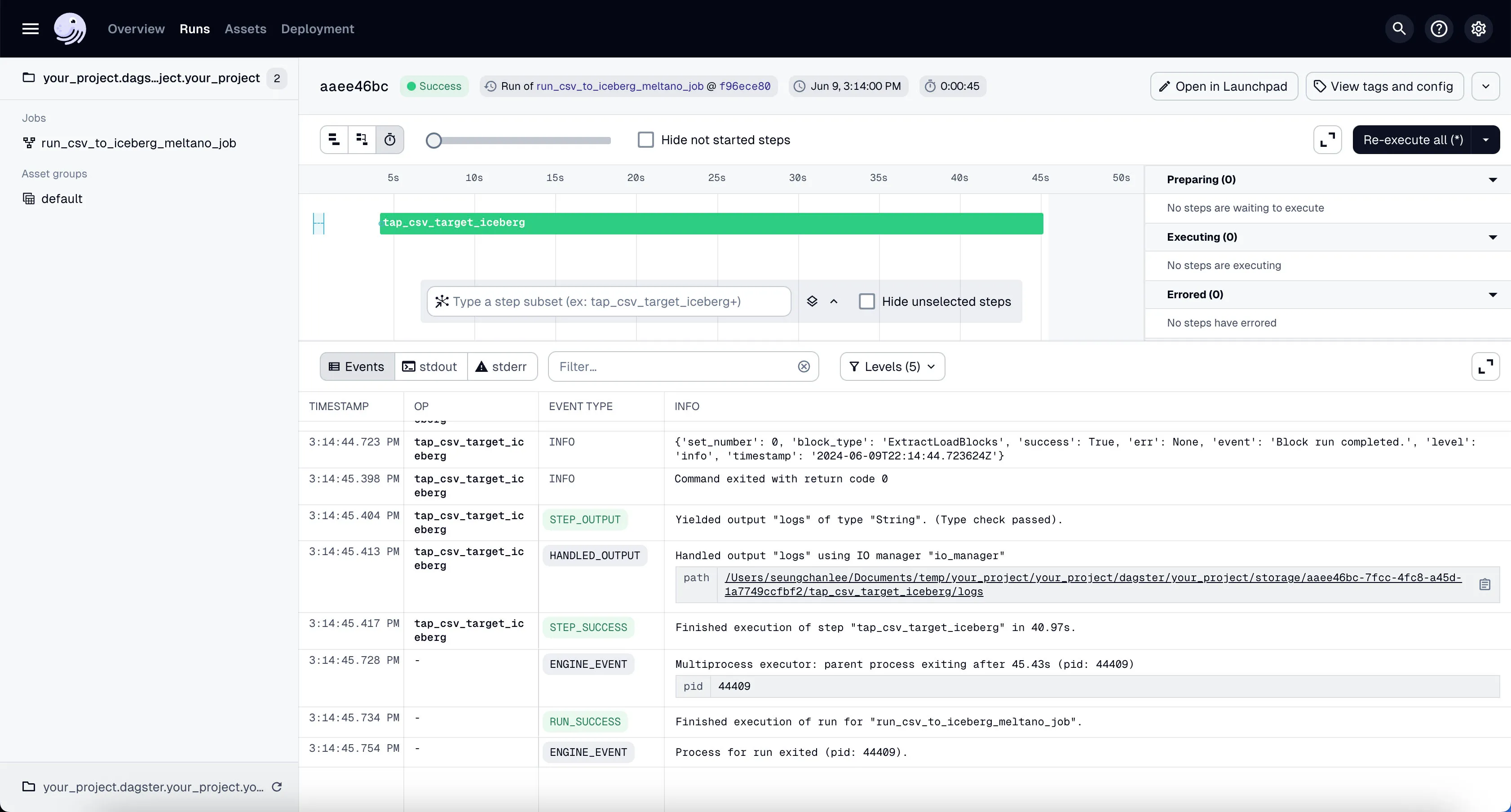
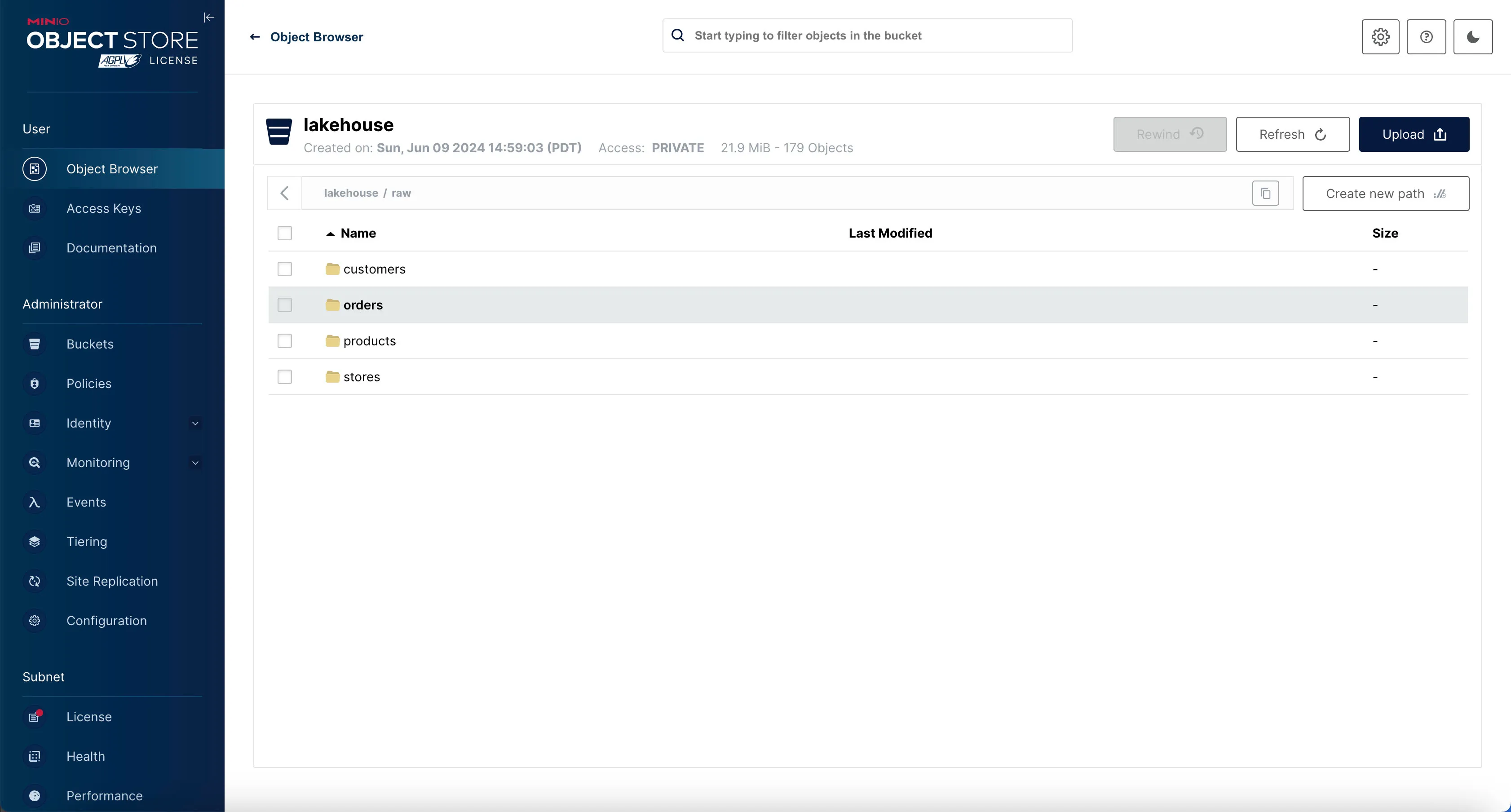
If the job is run successfully, you’ll see the 4 different tables written inside Minio’s raw prefix (which maps to raw Trino schema).
Check it out in Minio by going to http://localhost:9000 and logging in with the username admin and password admin_secret.
Want to change the username/password for Minio?
Inspecting the Iceberg Tables with Trino
Once the data is inserted to the Iceberg tables, you can inspect them from inside the Trino shell.
Once you’re in the Trino shell, first you need to switch to the iceberg catalog and raw schema. This basically tells Trino we’re using the raw schema inside the Iceberg data store.
Trino catalog?
Then list out the tables in that schema.
Table
---------------
orders
customers
products
stores
(4 rows)To view the data inside the table, you can run something like:
This will show you the number of rows in the orders table.
_col0
--------
100000
(1 row)Data Transformation
Now that we have the data in the Iceberg tables, we can start the transformation process to turn the raw data into a more useful form for analytics.
Above, we briefly showed you how we used our query engine Trino to query the data in the Iceberg tables.
Using the Trino shell directly is great for data exploration and ad hoc queries, but it’s not suitable for an automated pipeline. For that, we connect DBT to Trino via the dbt-trino adapter so we can run our transformations inside Dagster (our orchestrator).
Now, let’s see how we can set up dbt and Trino to work together.
Here’s a quick reminder of where dbt and Trino are in the project structure.
your_project
├── .sidetrek
├── .venv
├── superset
├── trino
└── your_project
├── dagster
├── data
├── dbt
└── meltanoDBT + Trino
DBT is a SQL data transformation tool that follows software engineering best practices.
It makes it easy to write complex SQL queries, but it cannot execute those SQL queries itself. This is where Trino comes in. Trino is a query engine that can execute our DBT SQL queries.
DBT provides a Trino adapter (dbt-trino) that allows us to run our DBT transformations on Trino easily.
This Trino connection is configured in dbt/your_project/profiles.yml:
dbt_project:
target: trino
outputs:
...
trino:
type: trino
user: trino
host: localhost
port: 8080
database: iceberg
schema: project
http_scheme: http
threads: 1
session_properties:
query_max_run_time: 5dNotice the `schema` of `project`
In dbt/your_project/dbt_project.yml, you’ll see the project configuration.
name: demo_project_32
version: 1.0.0
profile: dbt_project
...There’s one more step required. We need to create the raw schema in Trino before we can run the DBT transformations.
We do this by adding the on-run-start hook inside dbt/your_project/dbt_project.yml.
...
on-run-start:
- CREATE SCHEMA IF NOT EXISTS raw
- CREATE SCHEMA IF NOT EXISTS {{ schema }}If you recall, it’s the Trino schema where we loaded the data from Meltano. Recall this command we ran inside Trino shell:
We previously set up the loader to load the data into the raw schema in the iceberg catalog.
Trino + Iceberg
Trino is a query engine (or “compute engine” to be more general).
But query engines need to know where the data is stored. If you want to dig up gold (our data), you need both the shovel (the compute engine, which is Trino) and the gold deposit (the storage, which is Iceberg + Minio).
In our case, the data is stored in Iceberg tables in Minio so we need to connect Trino with Iceberg somehow.
We’ve already set this up for you - if you look at the trino directory in the example project, you’ll see the iceberg.properties file inside /trino/etc/catalog directory. This is the file that connects Trino with Iceberg.
To learn more about this, see the Trino Iceberg connector documentation.
Staging, Intermediate, and Marts
OK, now we’ve set up all the tools required to write our transformation queries in DBT.
We can start writing SQL queries in DBT now, but instead, let’s take a look at a helpful organizational pattern: Staging, Intermediate, and Marts.
This is a common pattern in data warehousing where you have three layers of transformations, progressively turning raw data into a more business-conformed form suitable for analytics.
This pattern not only makes our SQL code more modular and maintainable but also makes it easier to collaborate with others. With a common design pattern like this, everyone knows exactly what to expect.
- Staging: This is where we create atomic tables from the raw data. You can think of each of these tables as the most basic unit of data — an atomic building block we’ll later compose together to build more complex SQL queries. This makes our SQL code more modular.
- Intermediate: This is where we compose a bunch of atomic tables from the staging stage to create more complex tables. You can think of this stage as an intermediate step between the modular tables in the staging stage and the final, business-conformed tables in the marts stage.
- Marts: This is where you have the final, business-conformed data ready for analytics. Each mart is typically designed to be consumed by a specific function in the business, such as the finance team, marketing team, etc.
For more details, we highly recommend you check out DBT’s excellent Best Practices Guide.
OK, now let’s take a look at how we set up each stage in our example project.
Staging
In dbt/your_project/models directory, you’ll see the staging directory.
Inside, you’ll find stg_iceberg.yml where we specify the data sources for the staging tables as well as define the staging tables (or “models” in DBT terms) themselves.
version: 2
sources:
- name: stg_iceberg
database: iceberg
schema: raw
tables:
- name: orders
- name: customers
- name: products
- name: stores
models:
- name: stg_iceberg__orders
- name: stg_iceberg__customers
- name: stg_iceberg__products
- name: stg_iceberg__storesNotice how we’ve specified in DBT that the data sources are in the iceberg database and the raw schema. This is because we’ve set up Trino to connect to Iceberg tables in the raw schema.
In other words, database here maps to Trino catalog.
Staging tables are then defined under models.
DBT file naming convention matters!
Example DBT Model in Staging
We won’t go through each table, but here’s an example of a DBT model stg_iceberg__orders.
{{
config(
file_format='iceberg',
on_schema_change='sync_all_columns',
materialized='incremental',
incremental_strategy='merge',
unique_key='order_id',
properties={
"format": "'PARQUET'",
"sorted_by": "ARRAY['order_id']",
}
)
}}
with source as (
select *, row_number() over (partition by id order by id desc) as row_num
from {{ source('stg_iceberg', 'orders') }}
),
deduped_and_renamed as (
select
CAST(id AS VARCHAR) AS order_id,
CAST(created_at AS TIMESTAMP) AS order_created_at,
CAST(qty AS DECIMAL) AS qty,
CAST(product_id AS VARCHAR) AS product_id,
CAST(customer_id AS VARCHAR) AS customer_id,
CAST(store_id AS VARCHAR) AS store_id
from source
where row_num = 1
)
select * from deduped_and_renamedI’m sure you recognize the SQL queries here. The part you might not be familiar with is the config block at the top.
This is actually a Jinja template that DBT uses to augment SQL code. In this case, we’re telling DBT how to materialize this model.
When we run DBT build, it will take this code and create a valid SQL query that can be executed by Trino.
Adding Staging Model Configuration to dbt_project.yml
Finally, we need to add a bit of extra configuration. We do this in the dbt_project.yml file in the dbt directory.
...
models:
your_project:
staging:
+materialized: view
+schema: staging
+views_enabled: false
...Deduping
There’s one more thing we should go over: deduping.
Because target-iceberg currently only supports APPEND operation, you will probably want to dedupe the data during the staging stage of the DBT transformation.
This way you can make sure the ingestion process is idempotent (i.e. you can run it multiple times with the same result).
There are many ways to dedupe your data here, but let’s see how we did it in the example project.
Before we get to the code, let’s enter the Trino shell and see how many rows are in the raw orders table (i.e. ingested frmo Meltano before any transformation).
You’ll see that we have 100k rows in the raw orders table as expected (since our source orders.csv has 100k rows).
_col0
---------
1000000
(1 row)Once we run the staging DBT models, we can see that stg_iceberg__orders table also has 100k rows as expected.
The output should be:
_col0
---------
1000000
(1 row)Now, if we run the Meltano ingestion job AGAIN in Dagster, we’ll see that the orders table in Trino will have 200k rows. This is because target-iceberg APPENDs the data.
You should see:
_col0
---------
2000000
(1 row)Clearly we don’t want this to happen in our staging model since we don’t want any duplicate data.
To dedupe the data, we add the row_num column to the source raw orders table by using the row_number() function in the stg_iceberg__orders model.
...
with source as (
select *, row_number() over (partition by id order by id desc) as row_num
from {{ source('stg_iceberg', 'orders') }}
),
deduped_and_renamed as (
select
CAST(id AS VARCHAR) AS order_id,
CAST(created_at AS TIMESTAMP) AS order_created_at,
CAST(qty AS DECIMAL) AS qty,
CAST(product_id AS VARCHAR) AS product_id,
CAST(customer_id AS VARCHAR) AS customer_id,
CAST(store_id AS VARCHAR) AS store_id
from source
where row_num = 1
)
select * from deduped_and_renamedThis code adds a row number to duplicate rows based on id field. For example, if we have two rows with the same id, the row with the higher id will have row_num of 1 and the other will have row_num of 2.
id | row_num
1 | 1
1 | 2
2 | 1
3 | 1Then in deduped_and_renamed CTE, we only select rows where row_num is 1. This effectively dedupes the data.
Now if you go back to the Trino shell and run the query to see the number of rows in the stg_iceberg__orders table, you’ll see that it’s still only 100k.
The output should be:
_col0
---------
1000000
(1 row)We can do this for all tables in the staging area to make sure our ingestion process is idempotent at the staging stage.
Intermediate
Similar to the staging stage, we have the intermediate stage in the dbt/your_project/models/intermediate directory.
As with staging, you’ll notice we specify the sources and models in the int_iceberg.yml file.
version: 2
sources:
- name: int_iceberg
database: iceberg
schema: project_staging
tables:
- name: stg_iceberg__orders
- name: stg_iceberg__customers
- name: stg_iceberg__products
- name: stg_iceberg__stores
models:
- name: int_iceberg__denormalized_ordersThen we add the model SQL file int_iceberg__denormalized_orders.sql.
{{
config(
file_format='iceberg',
materialized='incremental',
on_schema_change='sync_all_columns',
unique_key='order_id',
incremental_strategy='merge',
properties={
"format": "'PARQUET'",
"sorted_by": "ARRAY['order_id']",
"partitioning": "ARRAY['device_type']",
}
)
}}
with denormalized_data as (
select
o.order_id,
o.order_created_at,
o.qty,
o.product_id,
o.customer_id,
o.store_id,
c.acc_created_at,
c.first_name,
c.last_name,
-- Concatenated columns
CONCAT(c.first_name, ' ', c.last_name) as full_name,
c.gender,
c.country,
c.address,
c.phone,
c.email,
c.payment_method,
c.traffic_source,
c.referrer,
c.customer_age,
c.device_type,
p.name as product_name,
p.category as product_category,
(p.price/100) as product_price,
p.description as product_description,
p.unit_shipping_cost,
s.name as store_name,
s.city as store_city,
s.state as store_state,
s.tax_rate,
-- Calculated columns
(p.price/100) * o.qty as total_product_price,
((p.price/100) * o.qty) + p.unit_shipping_cost as total_price_with_shipping,
(((p.price/100) * o.qty) + p.unit_shipping_cost) * (1 + s.tax_rate) as total_price_with_tax
from {{ ref('stg_iceberg__orders') }} o
left join {{ ref('stg_iceberg__customers') }} c
on o.customer_id = c.id
left join {{ ref('stg_iceberg__products') }} p
on o.product_id = p.id
left join {{ ref('stg_iceberg__stores') }} s
on o.store_id = s.id
)
select *
from denormalized_dataFinally in dbt/dbt_project.yml, we add the configuration for the intermediate stage.
...
models:
your_project:
staging:
+materialized: view
+schema: staging
+views_enabled: false
intermediate:
+materialized: view
+schema: intermediate
+views_enabled: false
...Marts
Same deal with marts. We have the dbt/your_project/models/marts directory where we specify the sources and models in the mart_iceberg.yml file.
version: 2
sources:
- name: marts_iceberg
database: iceberg
schema: project_intermediate
tables:
- name: int_iceberg__denormalized_orders
models:
- name: marts_iceberg__general
- name: marts_iceberg__marketing
- name: marts_iceberg__paymentTake note of the Marts naming convention.
Then we add the model SQL files. We’ll skip an example here, but you get the idea.
Finally, we add the configuration for the marts stage in dbt/dbt_project.yml.
...
models:
your_project:
staging:
+materialized: view
+schema: staging
+views_enabled: false
intermediate:
+materialized: view
+schema: intermediate
+views_enabled: false
marts:
+materialized: view
+schema: marts
+views_enabled: false
...Running DBT Transformations in Dagster
Now that we have the DBT transformations set up, let’s see how we can run them in Dagster.
Dagster has a deep DBT integration. It can infer the dependencies between all your DBT models and run them in the correct order. The visualization of this graph is also very helpful.
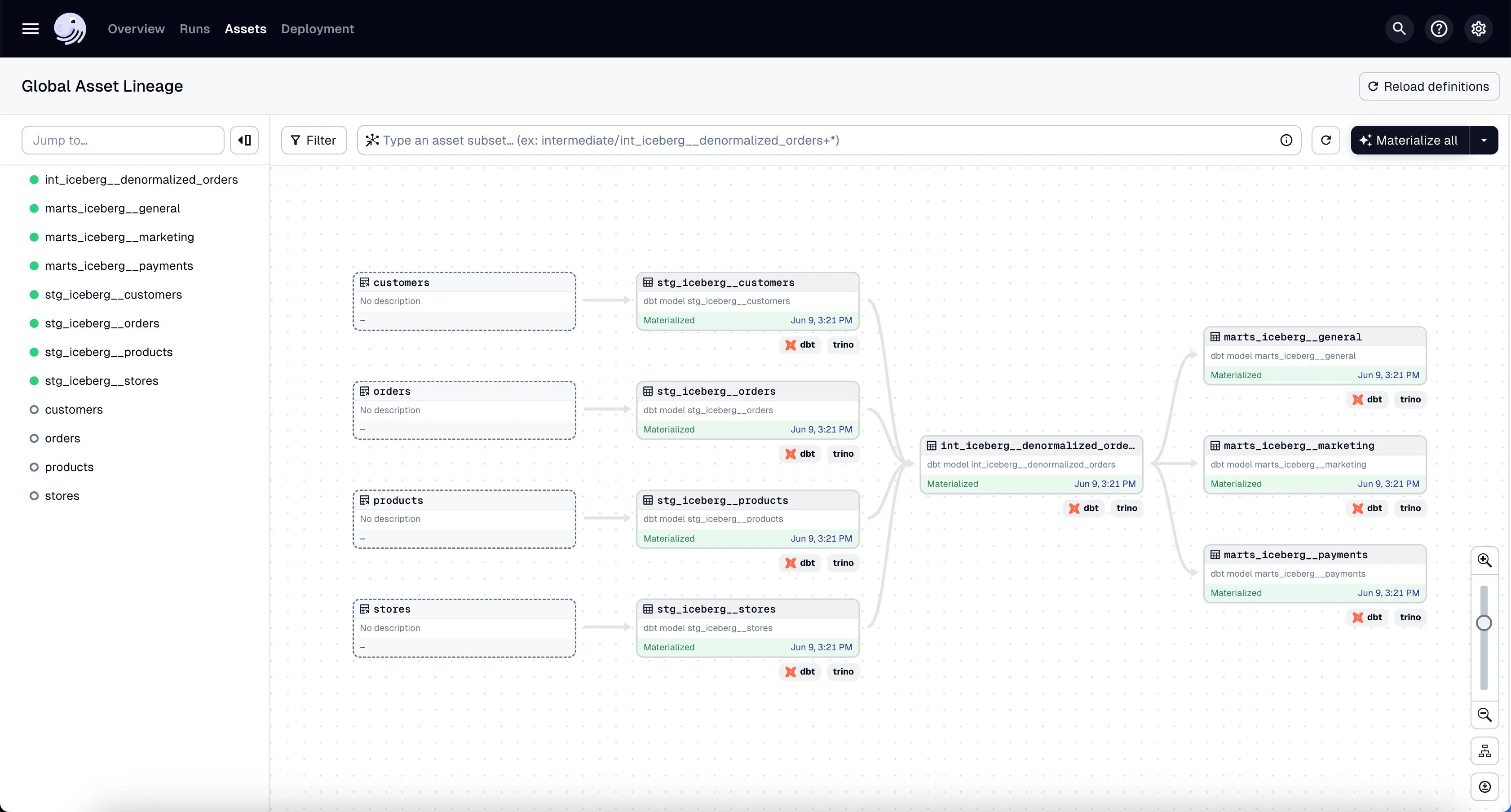
We add all DBT assets into Dagster in dagster/your_project/your_project/dbt_assets.py.
...
@dbt_assets(manifest=dbt_manifest_path)
def dbt_project_assets(context: AssetExecutionContext, dbt: DbtCliResource):
yield from dbt.cli(["build"], context=context).stream()In the code above, we’re using the dagster_dbt package, which the Dagster team created to import DBT models as Dagster “assets”.
What are Dagster "assets"?
Once we’ve done that, we can add the DBT assets to the Dagster definitions in dagster/your_project/your_project/__init__.py.
import os
from dagster import Definitions
from dagster_dbt import DbtCliResource
from .dbt_assets import dbt_project_assets, dbt_project_dir
from .meltano import run_csv_to_iceberg_meltano_job
defs = Definitions(
assets=[dbt_project_assets],
jobs=[run_csv_to_iceberg_meltano_job],
resources={
"dbt": DbtCliResource(project_dir=os.fspath(dbt_project_dir)),
},
)Now you should be able to see all DBT assets in Global Asset Lineage section of the Dagster dashboard:
- Click on the “Assets” in the top menu.
- Click on “View global asset lineage” at the top right.
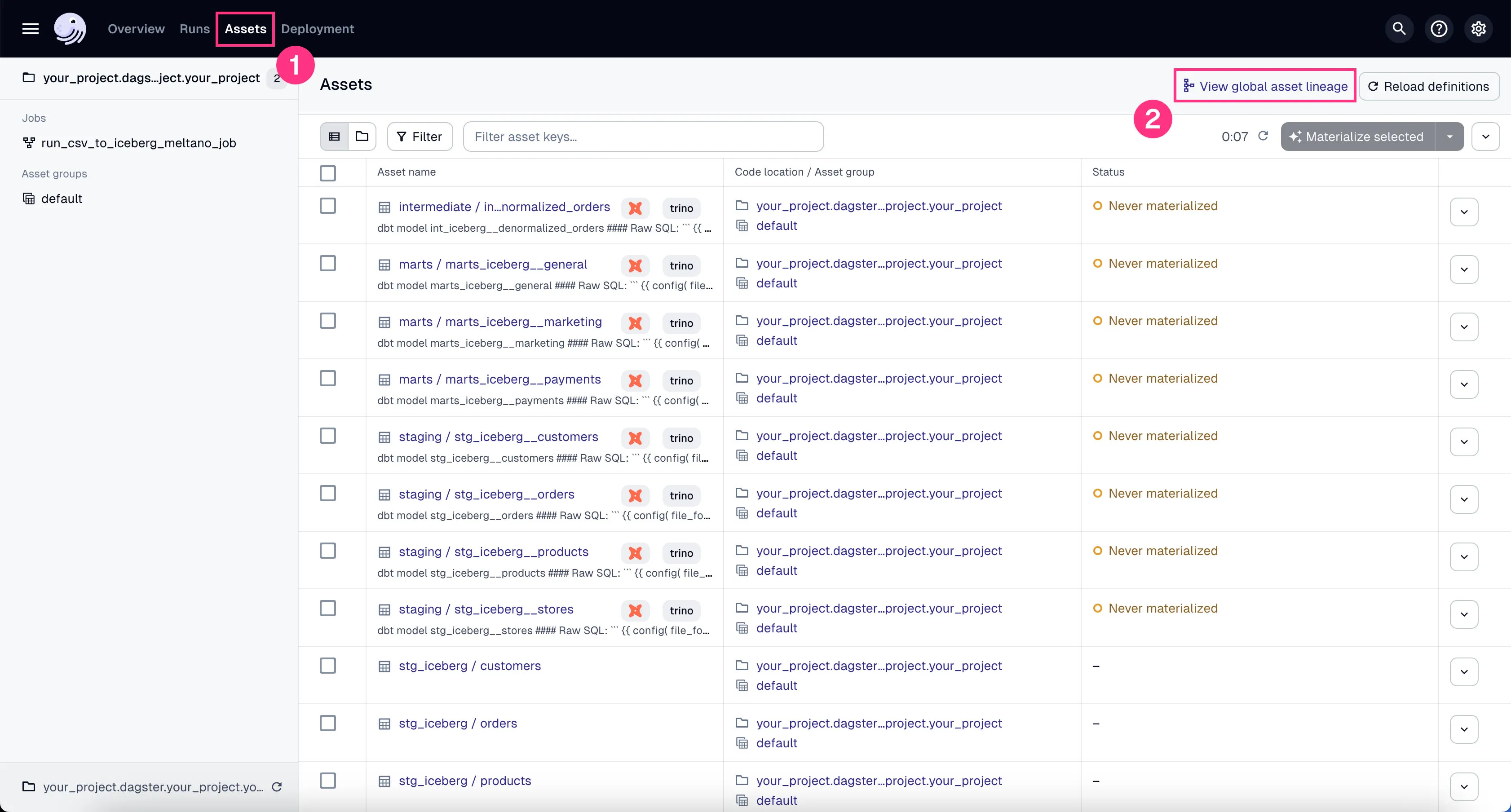
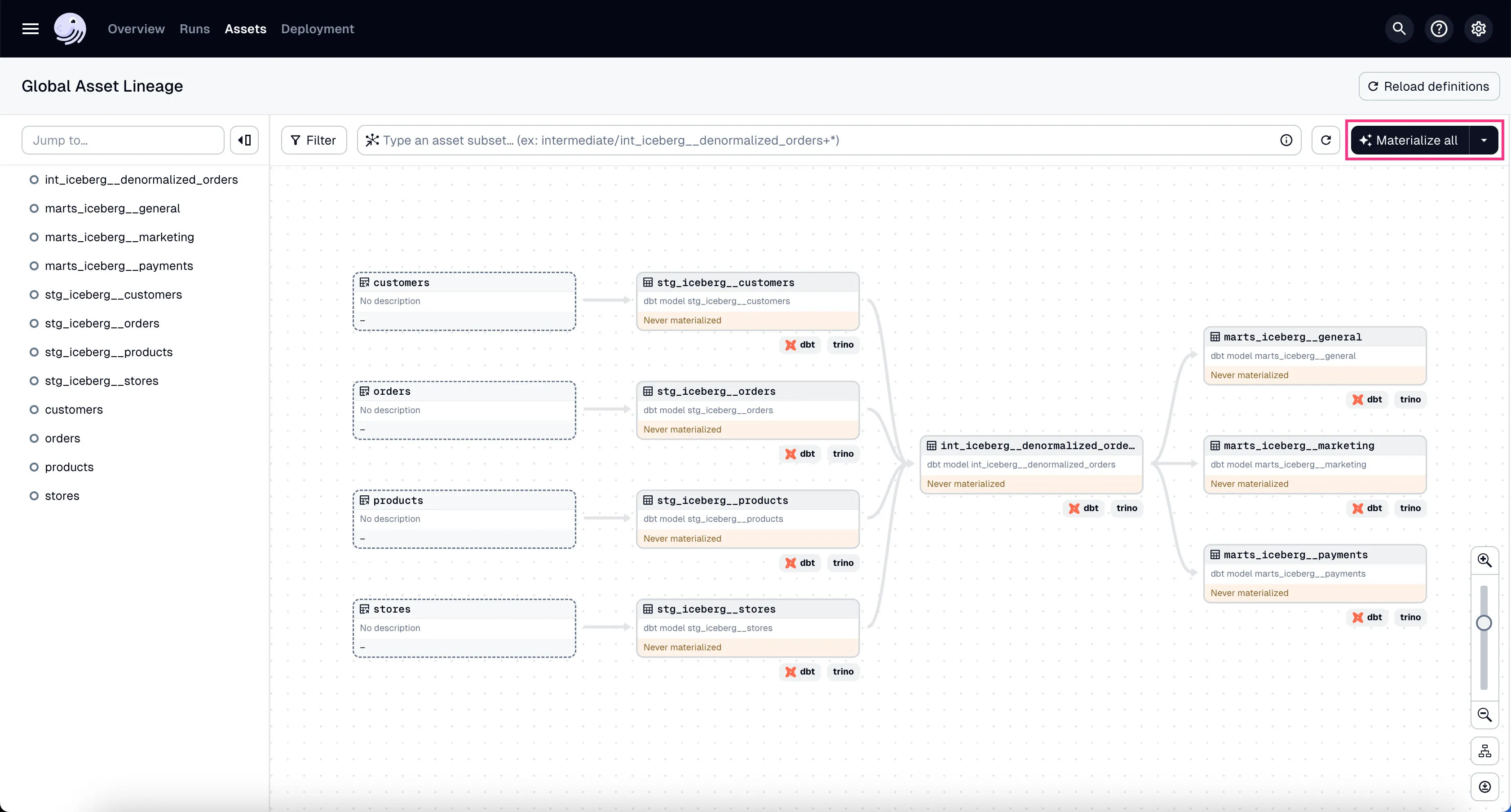
In the global asset lineage view, click “Materialize all” to execute the DBT transformations (underneath, Trino is executing these DBT queries). Of course, in a production environment, you might want to schedule them instead of manually triggering them.
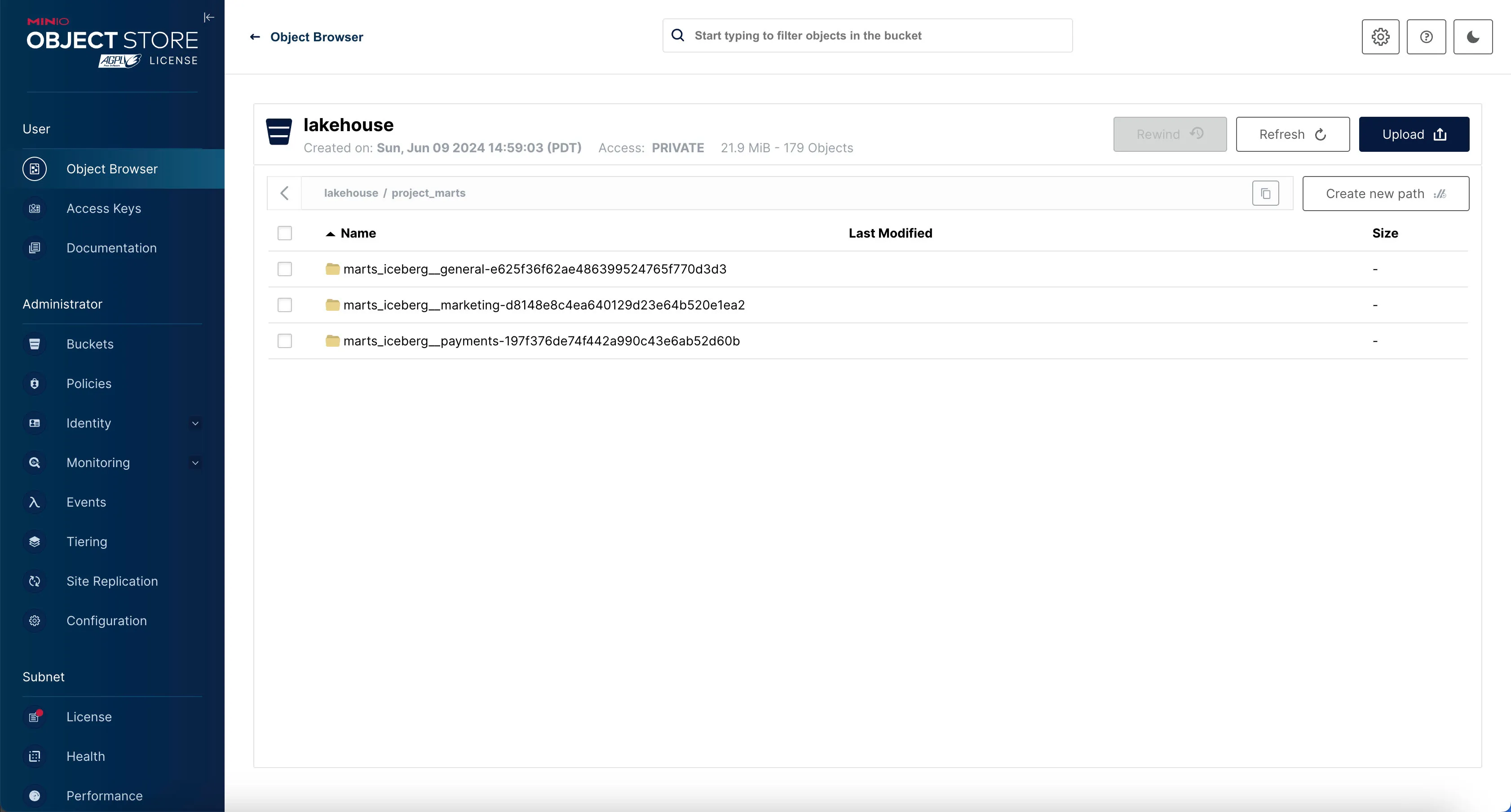
If the materialization was successful, you should see 3 analytics-ready tables in project_marts prefix in minio.
Data Visualization
OK, we have the data in the form we want for analytics!
Now we can visualize them using a tool like Superset.
We know that Data Analysts are particular about which tool they use here. So we’ve separated out Superset in its own directory so it can be easily replaced by another tool of your choice.
your_project
├── .sidetrek
├── .venv
├── superset
├── trino
└── your_project
├── dagster
├── data
├── dbt
└── meltanoLet’s configure Superset to connect to Trino and visualize the data.
Superset + Trino
Go to the Superset dashboard at http://localhost:8088 and log in with the username admin and password admin.
You can change the username and password in the docker-init.sh file inside the superset/docker directory:
...
ADMIN_PASSWORD="admin"
...
# Create an admin user
echo_step "2" "Starting" "Setting up admin user ( admin / $ADMIN_PASSWORD )"
superset fab create-admin \
--username admin \
--firstname Superset \
--lastname Admin \
--email admin@superset.com \
--password $ADMIN_PASSWORDAdding Trino as a Database Connection in Superset
Now we need to add Trino as a database connection in Superset.
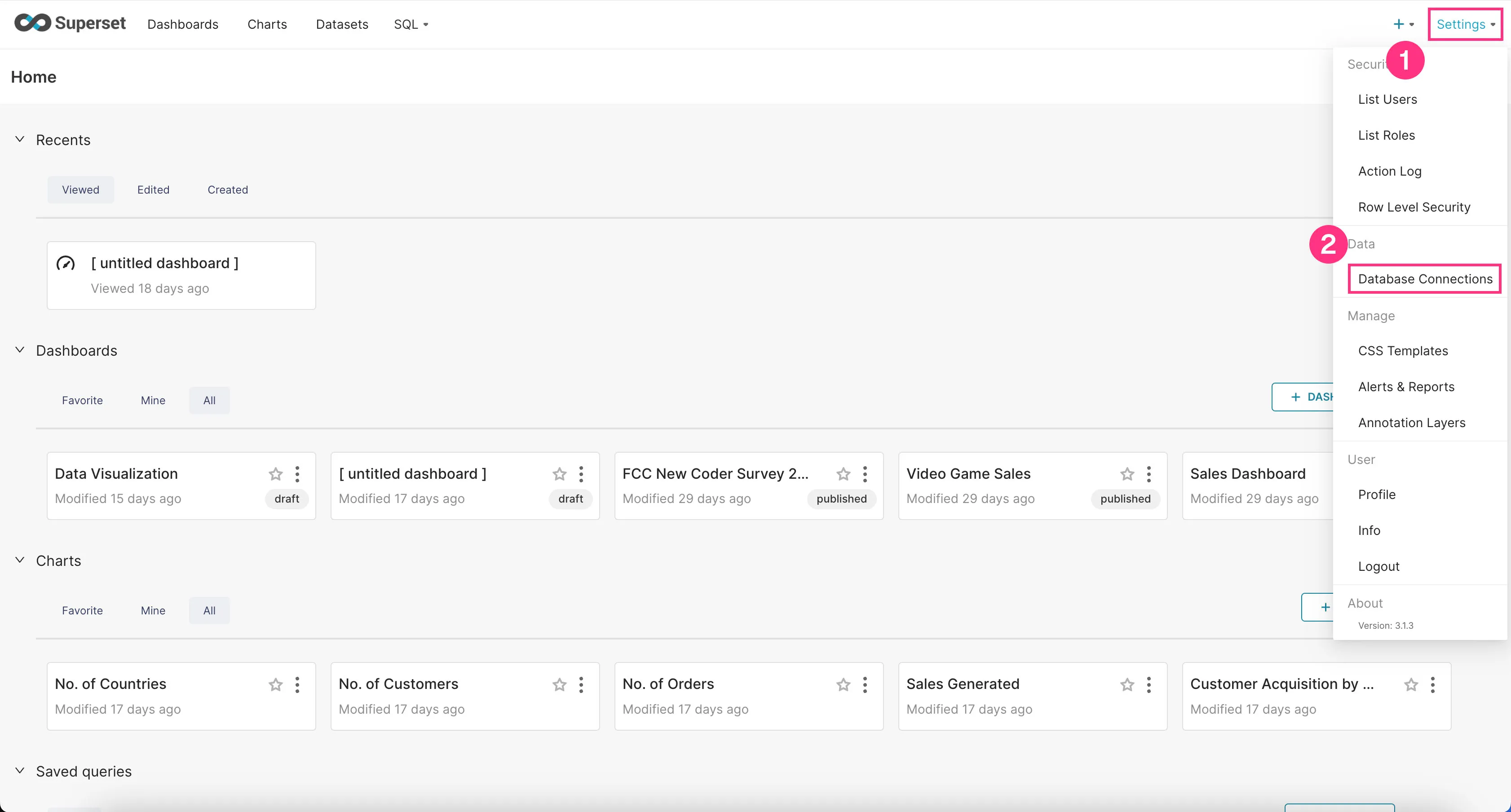
- Go to the “Settings” dropdown at the top right corner and click “Database Connections”.
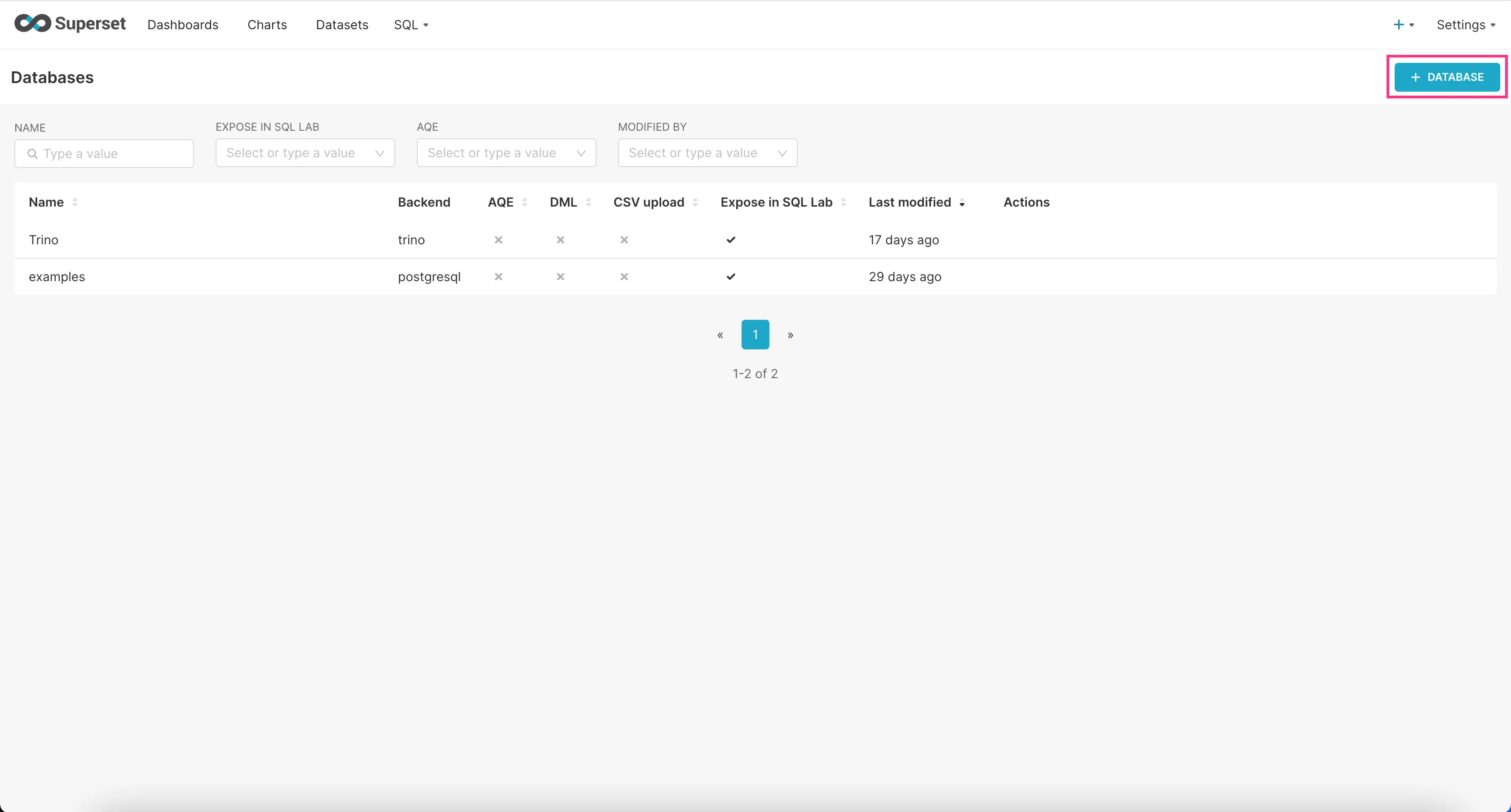
- Click on the “+Database” button at the top right corner.
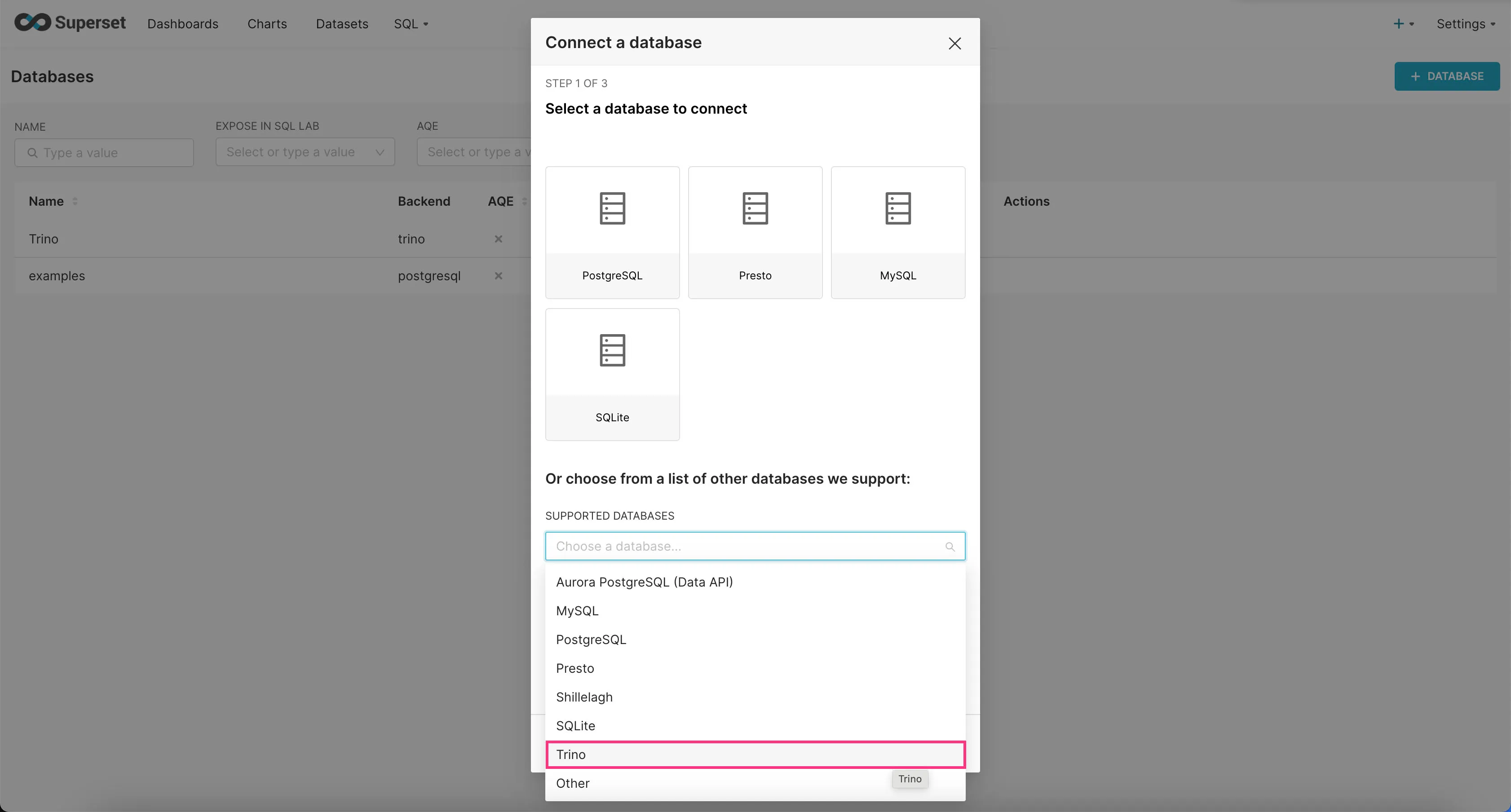
- Find “Trino” option in the “SUPPORTED DATABASES” select field near the bottom.
- In the “SQLALCHEMY URI” field, enter
trino://trino@host.docker.internal:8080/icebergand then click “Connect”.
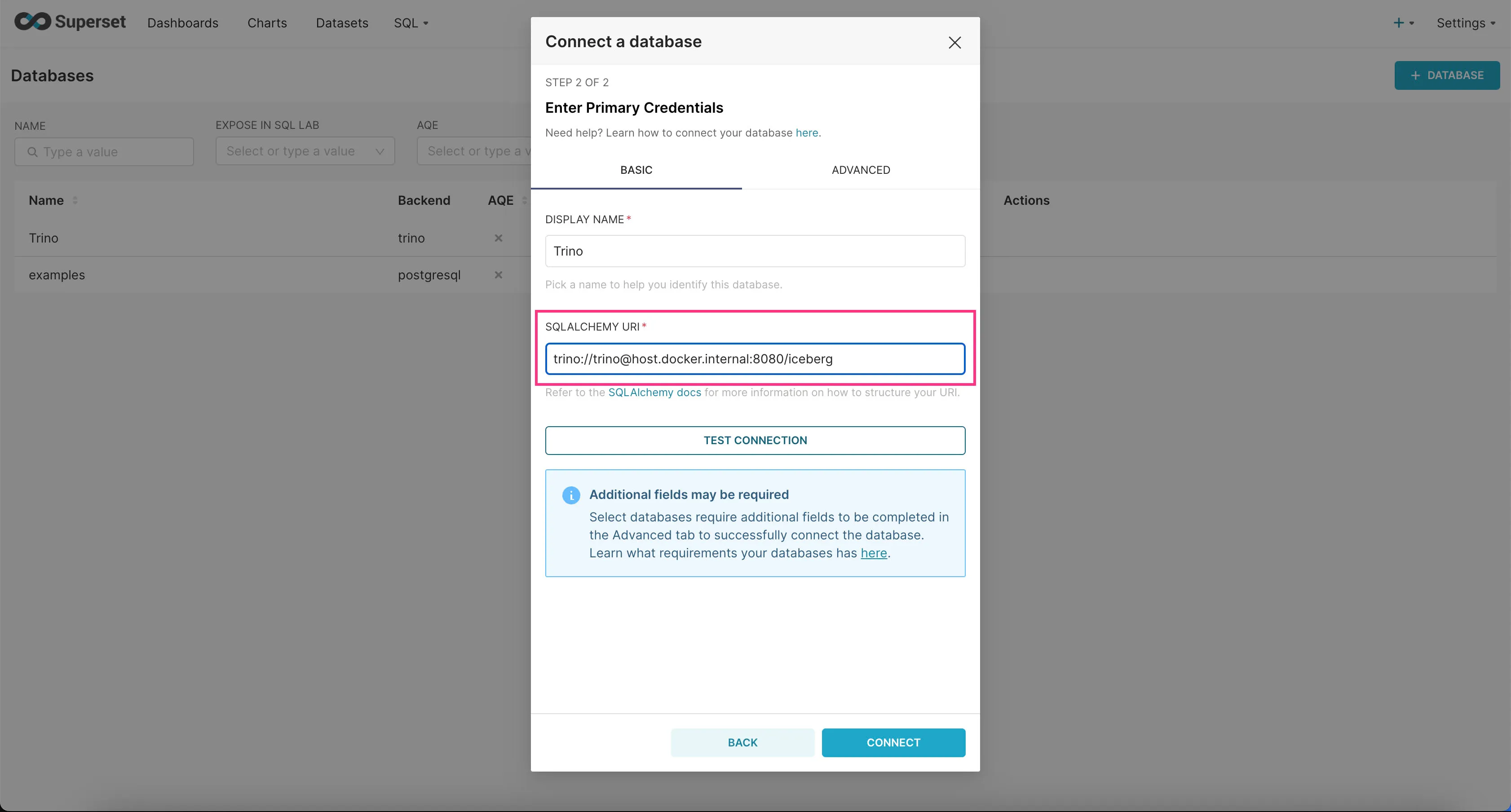
Trino should now be connected to Superset.
Adding an Example Dashboard
Now that we’ve connected Superset to Trino, let’s add an example dashboard.
- First download the example dashboard we created for you here.
- Go to the “Dashboards” tab and click on the Import Dashboard icon at the top-right corner.
- Upload the downloaded zip file and click “Import”.
- Find the example dashboard you just added in the list of dashboards and click on it to view it.
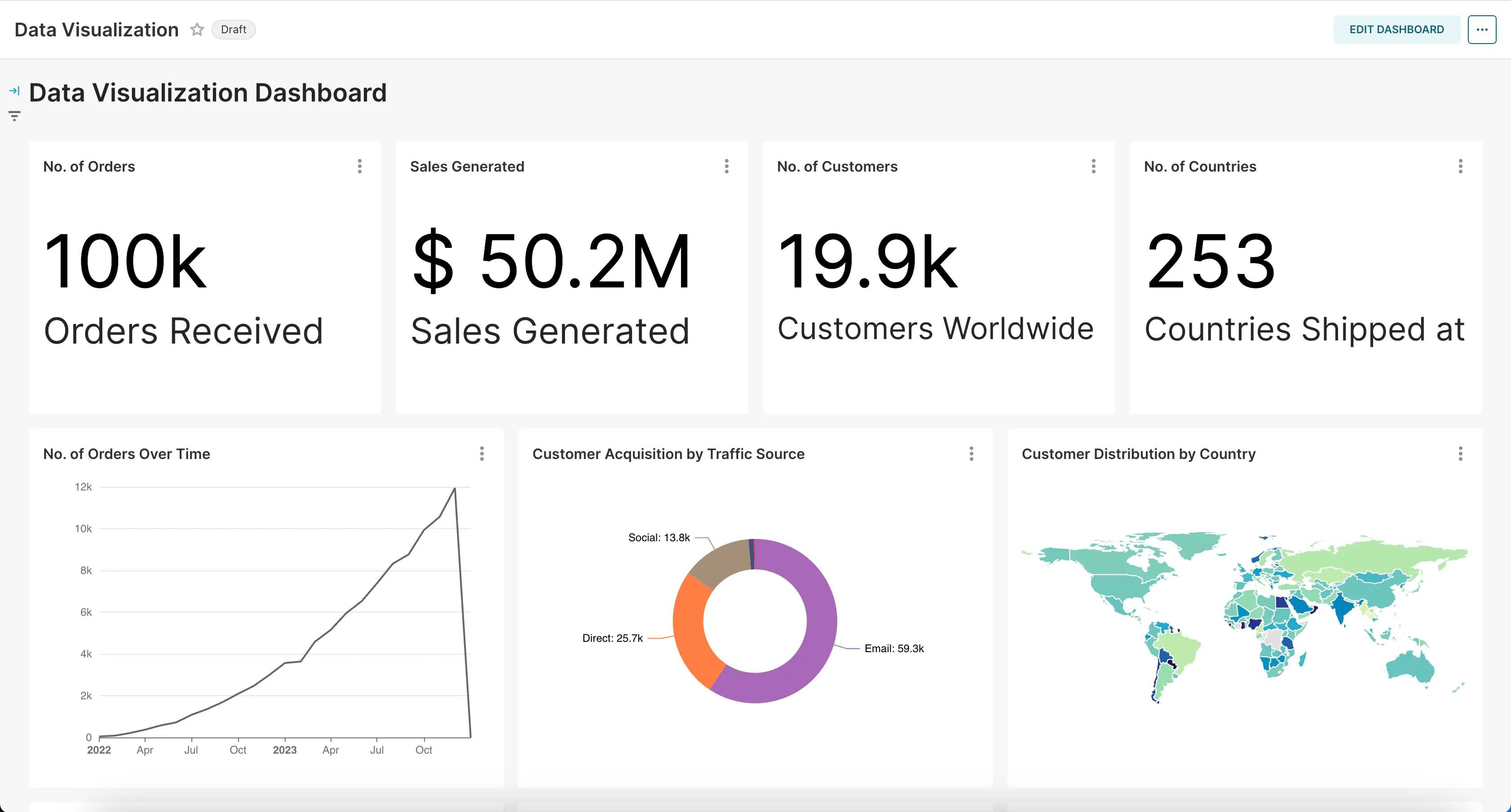
That’s it! You should now see a bunch of charts we created for you based on the example dataset.
Next Steps
Congratulations! You’ve just built an end-to-end data pipeline from scratch.
This is a simple example, but it’s a great starting point for building more complex data pipelines.
If you have any questions or need help, feel free to reach out to us in our Slack community.